Table of Contents
Code and Resources Used
-
Packages: pandas, numpy, sklearn, matplotlib, seaborn, selenium
-
Scraper Github: https://github.com/arapfaik/scraping-glassdoor-selenium
-
Scraper Article: https://towardsdatascience.com/selenium-tutorial-scraping-glassdoor-com-in-10-minutes-3d0915c6d905
Web Scraping
- Tweaked the web scraper github repo (above) to scrape 1000 job postings from glassdoor.com. With each job, we got the following:
- Job title
- Salary Estimate
- Job Description
- Rating
- Company
- Location
- Company Headquarters
- Company Size
- Company Founded Date
- Type of Ownership
- Industry
- Sector
- Revenue
- Competitors
Data Cleaning
-
After scraping the data, I needed to clean it up so that it was usable for our model. I made the following changes and created the following variables:
-
Parsed numeric data out of salary
-
Parsed rating out of company text
-
Made a new column for company state
-
Added a column for if the job was at the company’s headquarters
-
Transformed founded date into age of company
Made columns for if different skills were listed in the job description:
- Python
- Excel
- AWS
- Spark
- Column for simplified job title and Seniority
- Column for description length
- Column for avarage salary
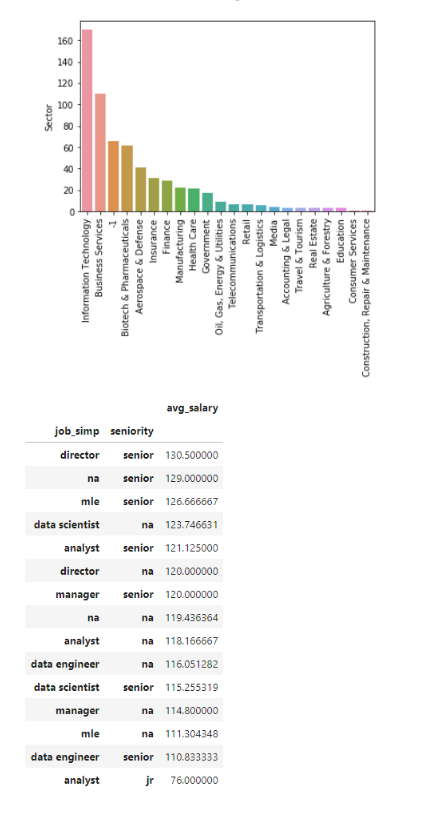
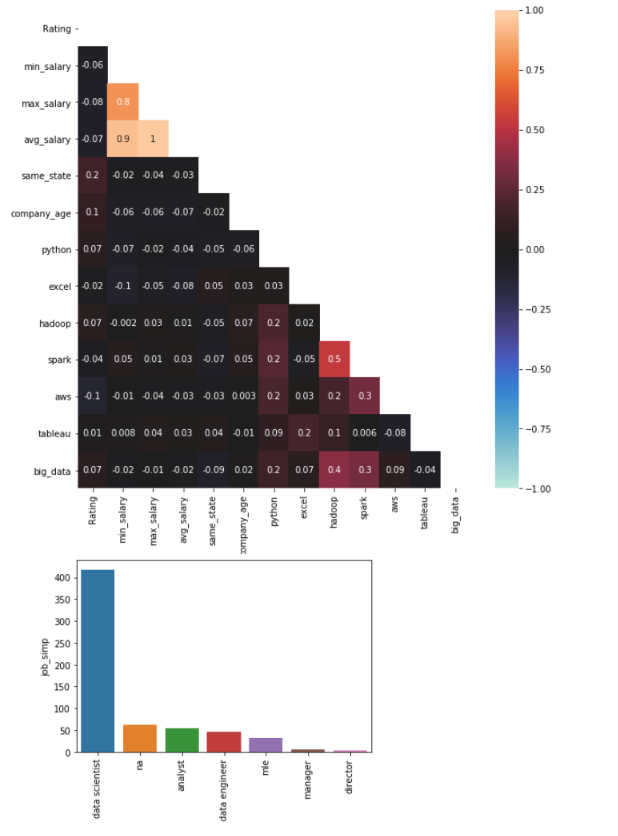
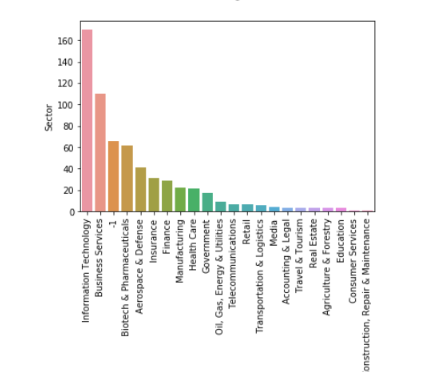
EDA